高可用:MongoDB容器部署
MongoDB 是一款 NoSQL 数据,通常用来存储非结构化数据,我们的产品中也有用到,例如:一些文件存储在 MongoDB 的 GridFS 中。
MongoDB 有三种方式来实现高可用:
- 副本集:副本集是 MongoDB 官方推荐的高可用解决方案。它通过在多个节点上复制数据来实现数据冗余和故障转移。副本集通常包括一个主节点和多个从节点,如果主节点发生故障,从节点可以自动选举出一个新的主节点,从而实现自动故障转移。
- 分片集群:分片集群是一种横向扩展的解决方案,可以将数据分散到多个节点上,从而提高读写性能和可伸缩性。分片集群通常由多个分片节点、多个配置节点和多个代理节点组成,其中分片节点负责存储数据,配置节点负责管理元数据,代理节点负责将客户端请求路由到正确的分片节点上。
- 复制集群:复制集群是一种基于副本集的解决方案,可以将多个副本集组合在一起,从而实现更高的可用性和可扩展性。复制集群通常由多个副本集节点和多个代理节点组成,其中代理节点负责将客户端请求路由到正确的副本集节点上。
本文中选择 MongoDB 的副本集的方式来进行演示,副本集相对简单,也能达到高可用的目的,架构图如下:
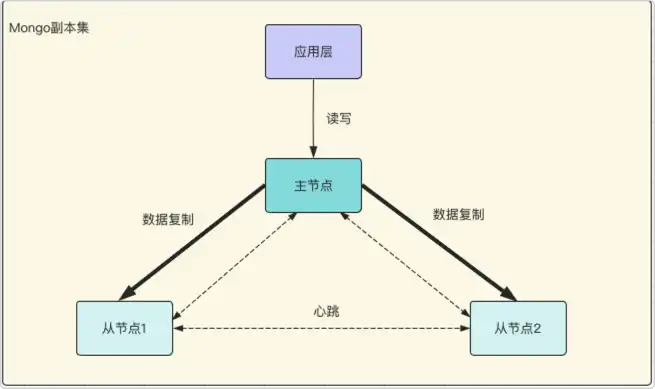
为了方便,在一台服务器上使用多个容器的方式来进行部署,真实场景下只需要把三个容器分别部署到三台服务器上即可,具体步骤如下:
1、准备一台 CentOS 服务器,安装好 Docker 和 docker-compose 。
2、在 /home 目录创建 mongodb 目录,进入 mongodb 目录创建 data 目录,data 目录中分别创建 mongo1、mongo2、mongo3 用来存放三个节点的数据。
3、使用命令 chmod -R 777 data 给 data 目录设置权限。
4、在 mongodb 目录中创建文件 docker-compose.yml ,用来构建容器,内容如下:
1 | version: '3' |
- ports:27017、27018、27019 分别为三个节点对外的端口
- volumes:将步骤 2 中创建的目录和容器内的数据目录进行映射
- –replSet rs0:指定副本集的名称为 rs0
- –bind_ip_all:可以让 MongoDB 实例能够通过所有网络接口进行连接,包括本地主机、局域网和互联网。这通常用于在多个计算机之间共享 MongoDB 数据库,或在具有可用公共 IP 地址的环境中使用。
5、在 mongodb 目录下执行 docker-compose up -d 进行容器的构建,成功后如下图:

6、随便进入一个 MongoDB 容器,下面命令为进入容器名 mongo1 的容器内部。
1 | docker exec -it mongo1 bash |
7、进入容器内部后,输入 mongo 命令进入 MongoDB 的命令行模式,在该模式执行下面的命令进行副本集的初始化:
1 | rs.initiate({_id: "rs0", members: [ |
- 该命令初始化一个名为 rs0 的副本集,并将三个 MongoDB 容器添加为成员。
- 注意:host 中指定的 IP 为服务器的 IP,当然如果使用的是容器 IP 或者容器名称,副本集和能正常启动和运行,但程序连接的时候就会出错 。
8、继续在 MongoDB 的命令行模式执行 rs.status() ,这个命令可以查看副本集的状态信息,包括成员、主节点和副本集配置。
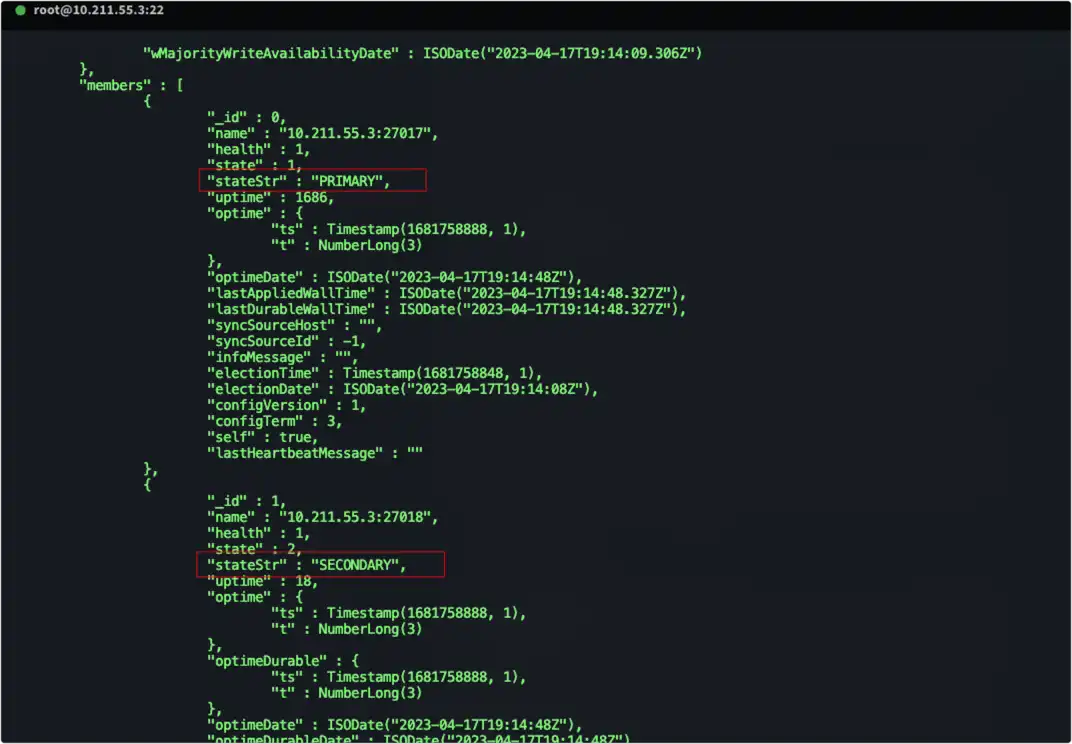
- Mongo1 被指定为了主(Primary),其余两个容器为副本(Secondary)
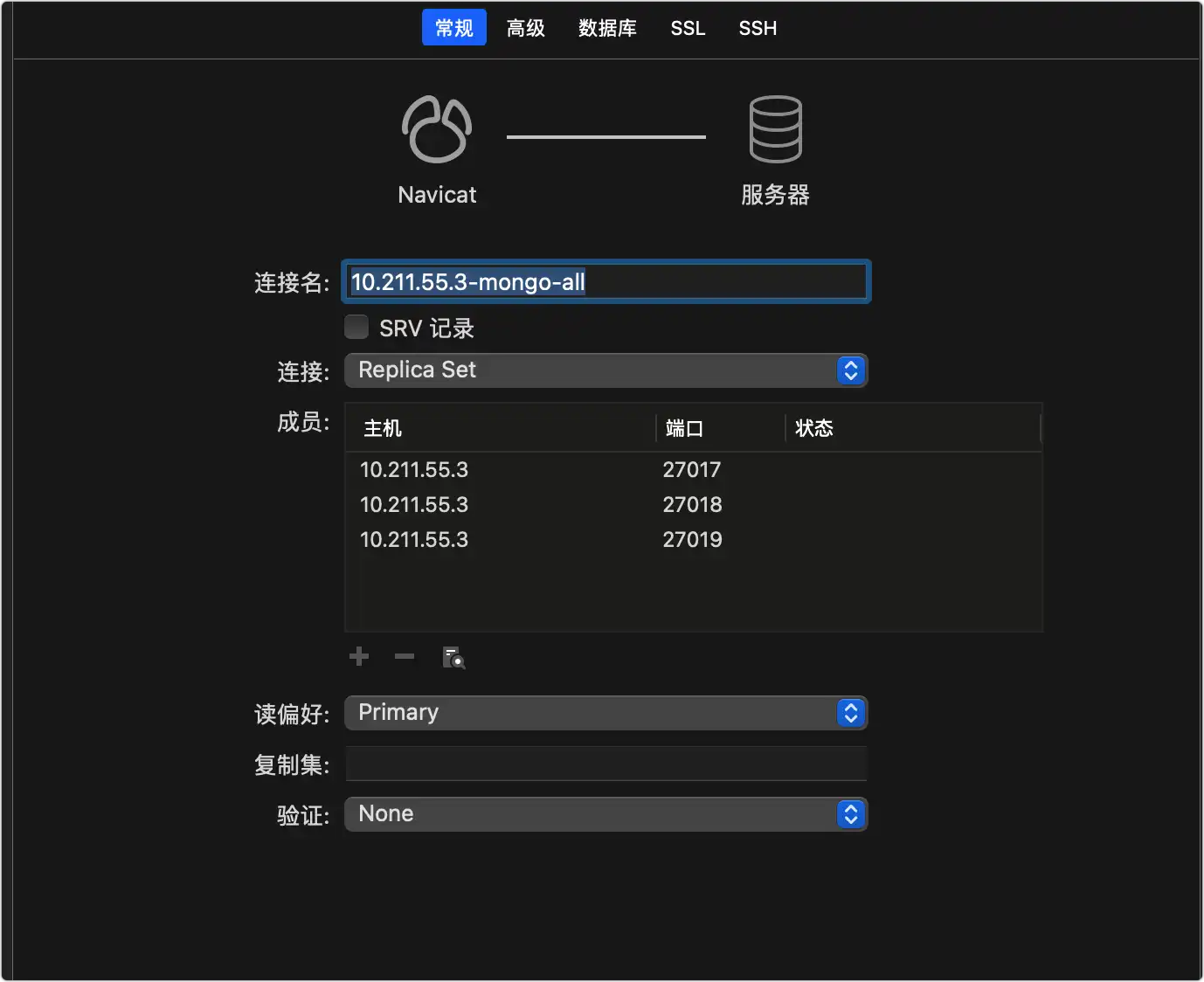
9、在 Navicat 中配置连接副本集,如下图:
10、到这里,MongoDB 在 Docker 中部署副本集就已经完成,接下来可以通过一些场景测试下是否能故障自动转移,我验证的场景如下:
- 重启虚拟机后检查 MongoDB 服务是否正常
- 使用命令
systemctl restart docker将 docker 重启,检查 MongoDB 服务是否正常 - 使用命令
docker stop mongo1将副本集中的主节点停掉,检查剩下的两个从节点是否能重现选举新的主节点 - 使用命令
docker start mongo1将之前的主节点启动,检查是否能自动切换为从节点 - 将 mongo2、mongo3 这两个从节点都停掉,检查 MongoDB 服务还是否可用,正常情况下应该是不可用,主节点 mongo1 会降级为从,变为只读,直连 mongo1 可以连接进行数据读取,集群无法连接。
- 上面每一步操作后,除了看状态之外,还需要用程序进行连接验证服务是否正常。
11、使用 .NET Core 程序进行验证,创建一个 .NET 6 的控制台程序,引用 NuGet 包 MongoDB.Driver 。
12、Program 类的代码如下:
1 | using MongoDB.Bson; |
- 连接字符串中的 replicaSet = rs0 用来指定副本集的名称
- readPreference=primary ,将读取偏好设置为主节点,表示只从主节点读取数据,这也是默认模式,除了 primary 外,还有一些其他的配置选项,说明如下:
readPreference=primaryPreferred:查询将首选主节点,但如果主节点不可用,则可以从其他节点读取数据。readPreference=secondary:查询将只从副本集的次要节点读取数据。如果没有次要节点可用,则查询将失败。readPreference=secondaryPreferred:查询将优先从次要节点读取数据,但如果没有次要节点可用,则可以从主节点读取数据。readPreference=nearest:查询将从网络延迟最低的节点读取数据。这个选项不考虑节点的角色(主节点或次要节点),而是选择网络最近的节点。
在高可用部署中,一定要结合实际情况进行权衡后,采取即能解决问题,又熟练掌握的方案,否则,出现问题,如果不能及时解决,效果还不如单机。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。




