ChatGPT 之后,再玩玩 Stable-Diffusion
前些天体验的 ChatGPT 主要用来进行文本方面的处理,那么图形有没有这样的 AI 工具
呢?答案是肯定的。
例如:和菜头公众号的题图和文章中的插图大多都是使用 Stable-Diffusion 的 AI 图形生成工具创作的。顺着 Stable-Diffusion 搜索了下相关资料,发现 AI 创作图片的工具也有不少:
- Disco Diffusion:是发布于 Google Colab 平台的一款利用人工智能深度学习进行数字艺术创作的工具,它是基于 MIT 许可协议的开源工具,可以在 Google Drive 直接运行,也可以部署到本地运行;
- Midjourney:是 Disco Diffusion 的原作者 Somnai 的作品,对 Disco Diffusion 进行了改进,平均 1 分钟能出图;
- DALL-E 2: OpenAI 推出 DALL·E 2, DALL-E 2 实现了更高分辨率和更低延迟;
- Stable-Diffusion:由 http://stability.ai/ 推出,在 2022 年 8 月 10 号开源了,10 几秒就能出图,算是比较快的了。
本文就以 Stable-Diffusion 为例,谈谈我的使用体验。Stable-Diffusion 作为一个开源工具,使用的方式有多种:
1、基于开源的工具提供了实现,比如官方提供的 https://beta.dreamstudio.ai/dream; ,也可以使用 https://huggingface.co/spaces/camenduru/webui
2、本地部署;
3、调用 API 。
官网注册账号
打开 https://beta.dreamstudio.ai/ ,直接选择使用 Google 账号进行注册,你也可以选择自己的方式。
相比较 ChatGPT ,dreamstudio 的注册要方便的多,注册成功后登录界面如下:
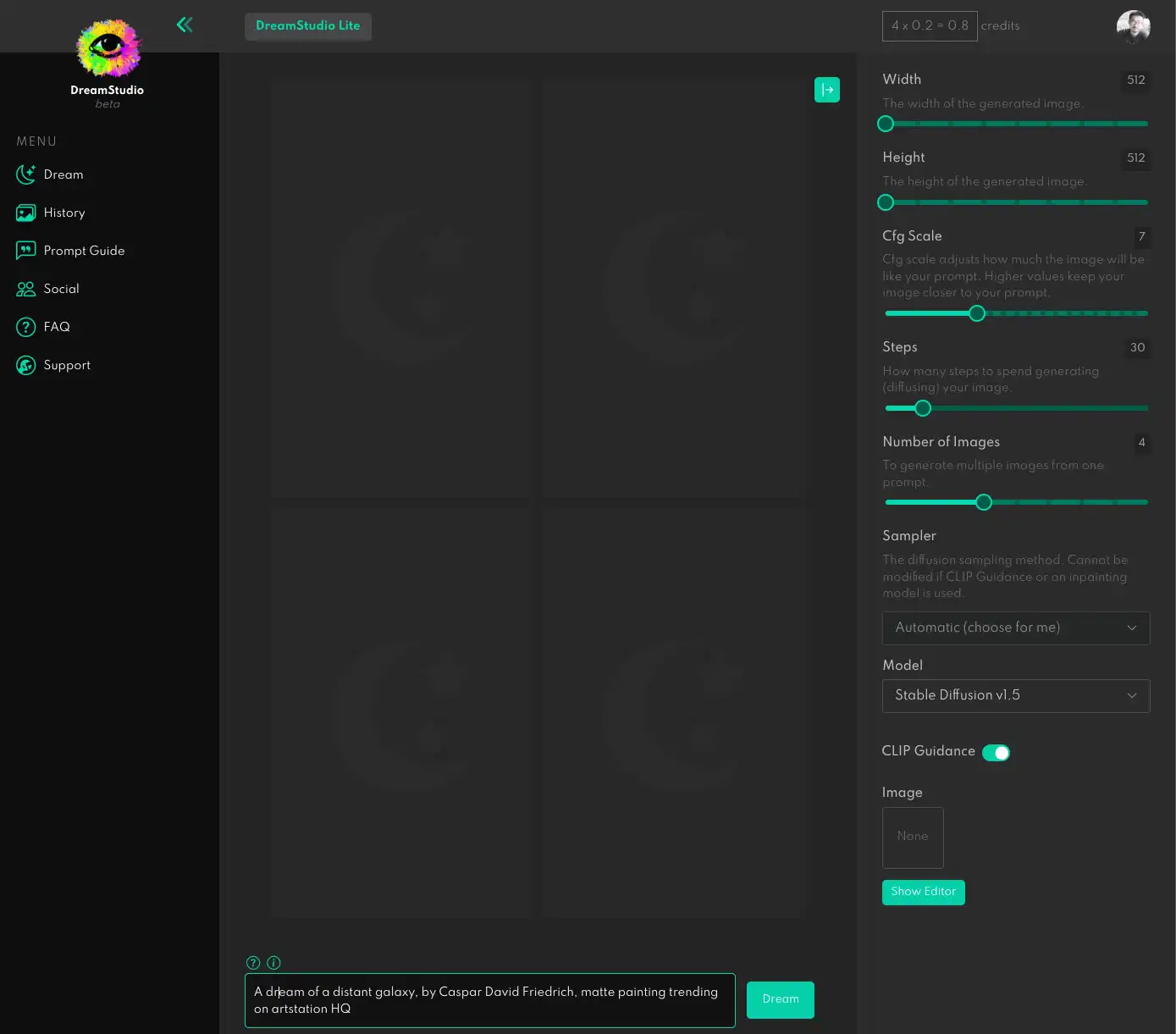
dreamstudio 是收费的,成功注册后会赠送 100 个 credits ,每次生成图片,会消耗一些
credits,消耗的多少跟设置有关,默认设置会产生 4 张 512 * 512 的图,消耗 0.8 个 credits 。
配置信息如下:
- Widht:图片宽度;
- Height:图片高度;
- Cfg Scale:一个阈值,越高生成的图片越接近你的描述,越低,AI 发挥空间越大,保持默认就好;
- Steps:生成图片用的步骤数,越大生成的越慢;
- Number of Images:一次生成的图片数量,默认为 4,也可以改为 1,改成 1 后,生成一次只要 0.2 credits。
在上图中最下面的文本框中输入提示文本,点击 Dream 按钮便可生成。
huggingface
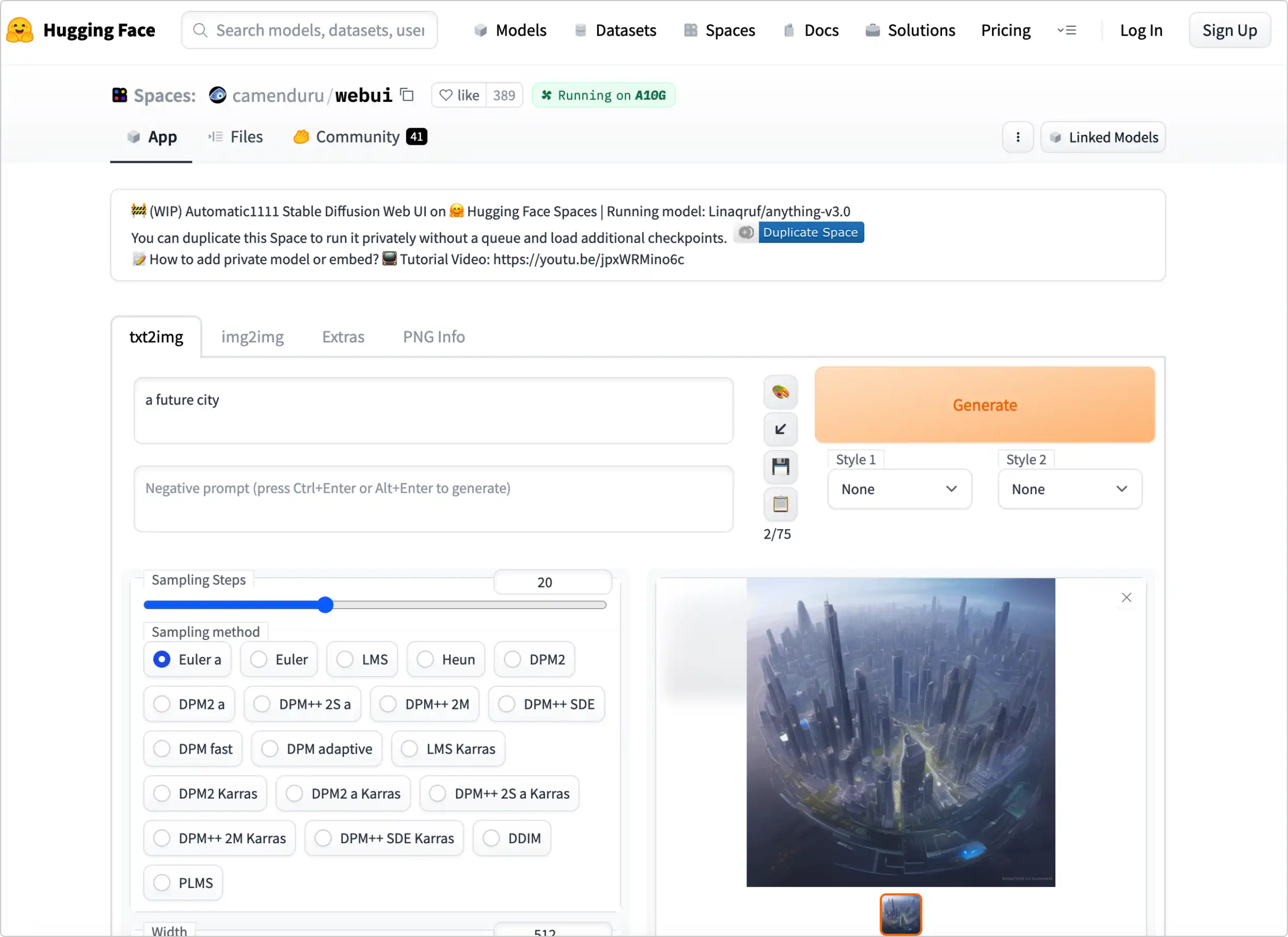
直接在浏览器输入:https://huggingface.co/spaces/camenduru/webui 便可使用,可以不用注册登录,缺点就是需要排队,相当于就是多人在同时使用这个服务,如果排队的人较多,生成的时间会比较长。
本地化部署
本地化部署对机器的配置要求比较高,内存和显存都不能太低。
在 GitHub 上有一个仓库 https://github.com/AUTOMATIC1111/stable-diffusion-webui 介绍了 stable-diffusion 怎样离线部署使用,提供了 Windows、Liunx、Mac 等多种方式。
如果你使用的是 Mac ,可以参考:https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Installation-on-Apple-Silicon
如果你使用的是 Windows ,觉得安装步骤比较繁琐,还有人做了一键安装和启动的项目放在 Github 上,地址如下:
https://github.com/EmpireMediaScience/A1111-Web-UI-Installer
提示语
AI 生成图片的关键在于提示语,就像使用 ChatGPT ,一个好的问题是关键。提示语不会写的话可以先参考,在下面网站中可以搜索相关的图片,查看提示语:
https://laion-aesthetic.datasette.io/laion-aesthetic-6pls/images
先多看看那些精美有创意的图片都是什么样的提示词生成的,看多了,再尝试自己去修改、调整。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。




