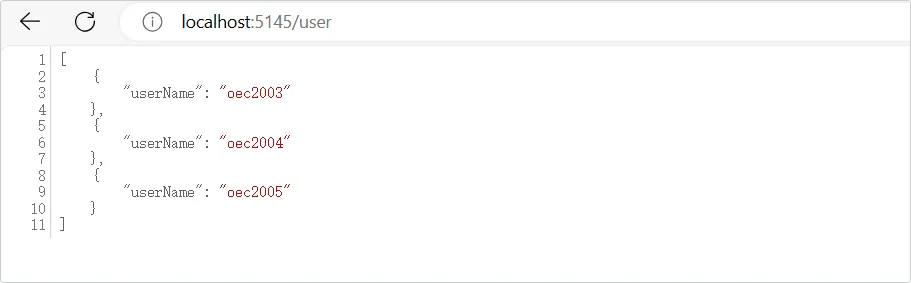
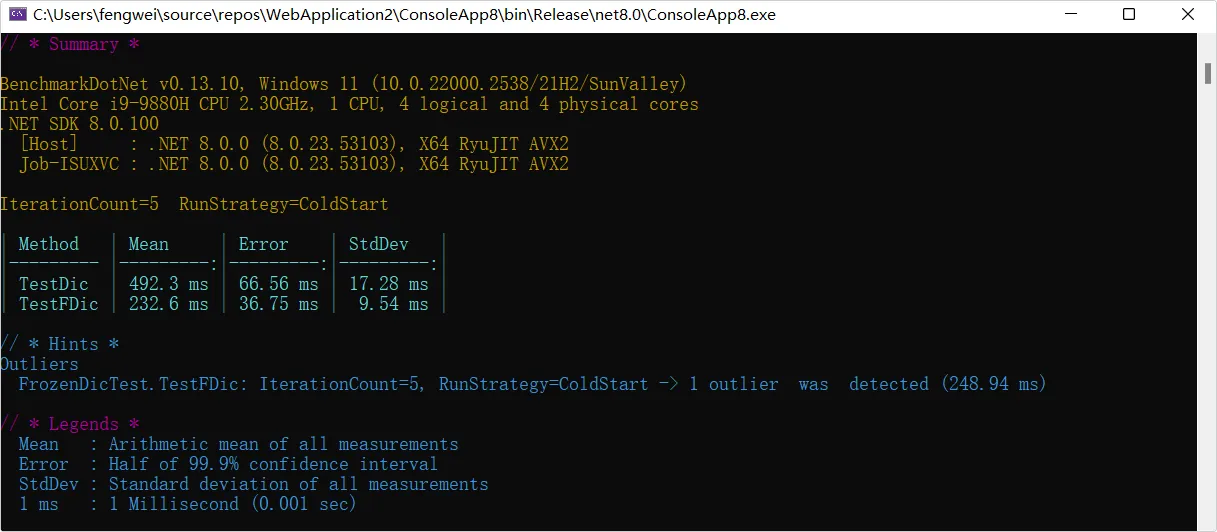
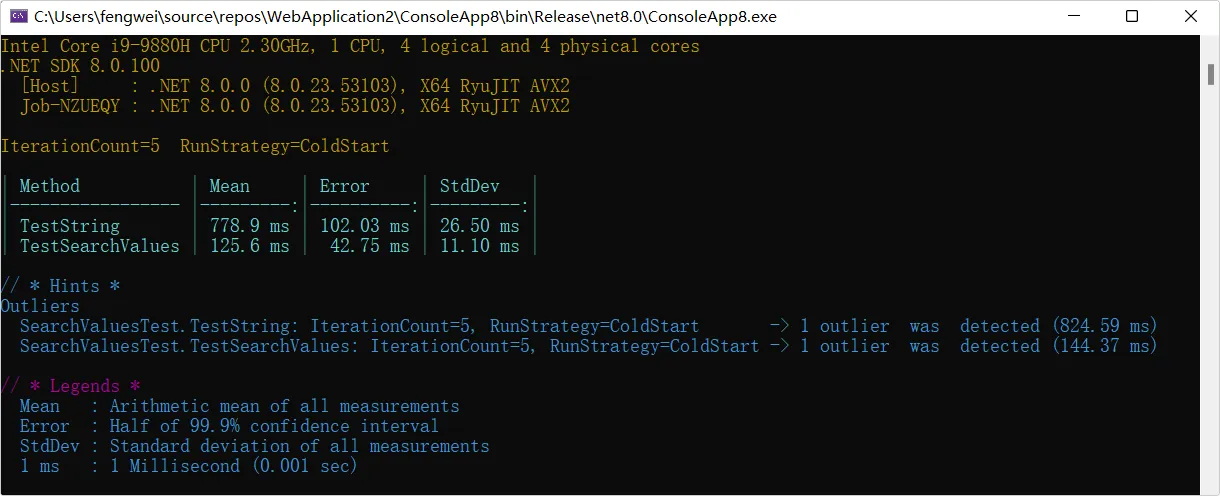
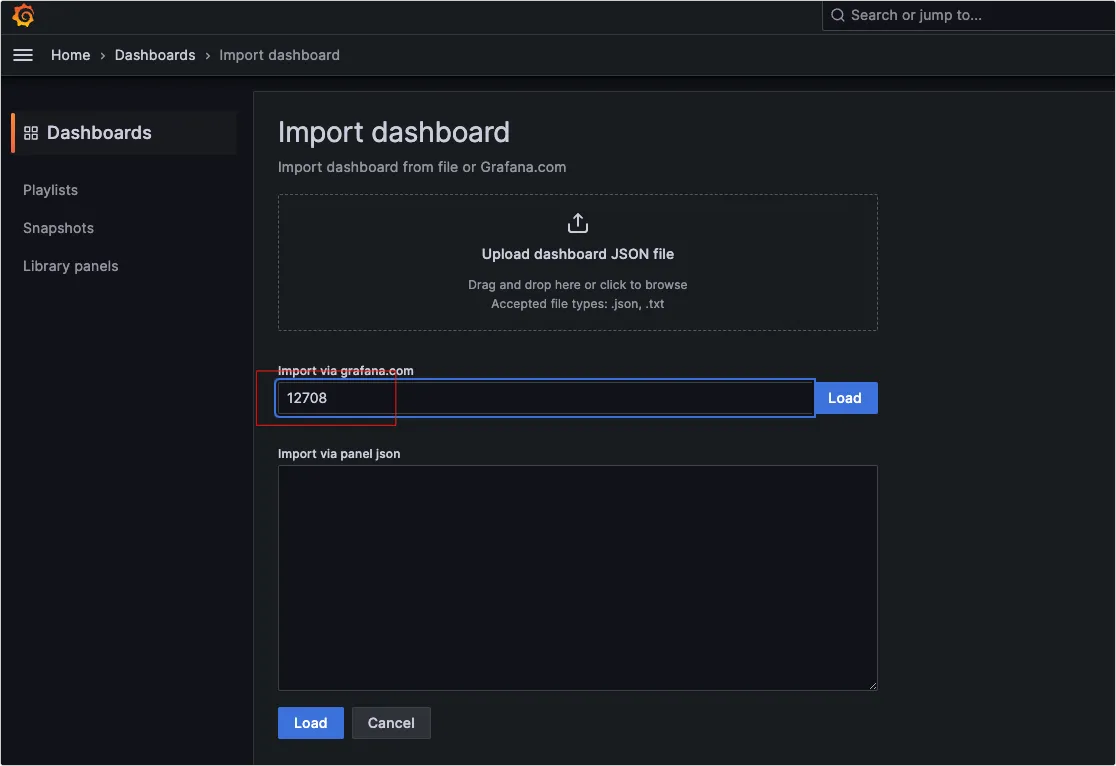
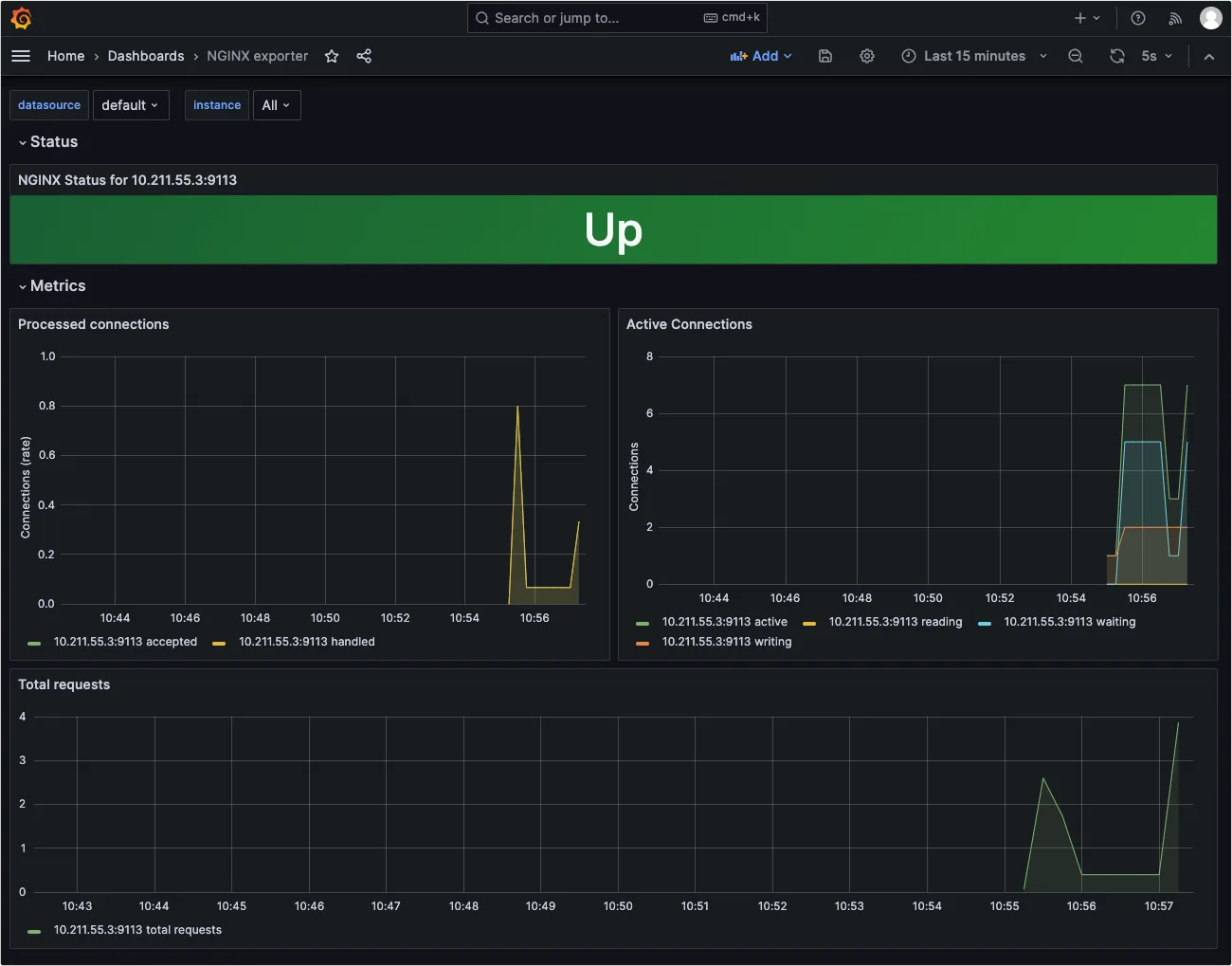
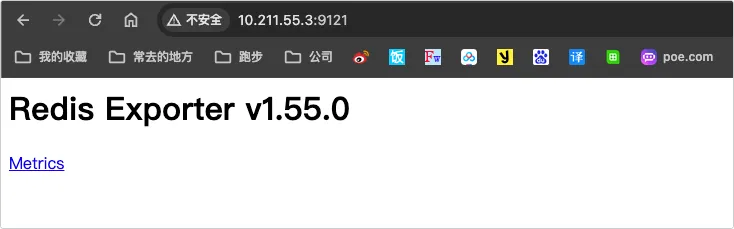
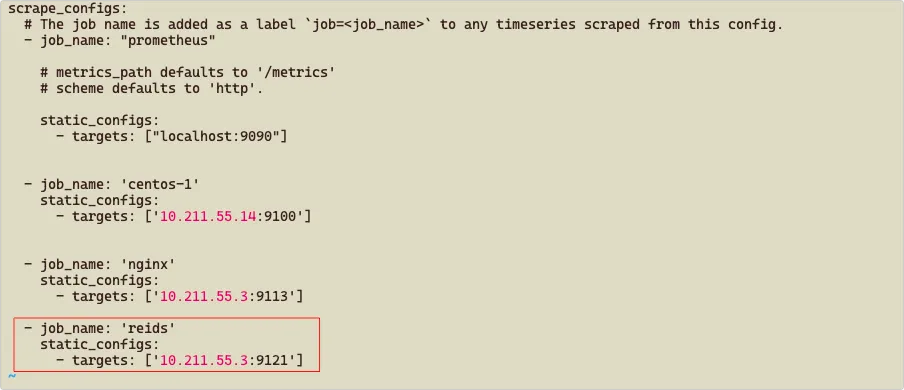
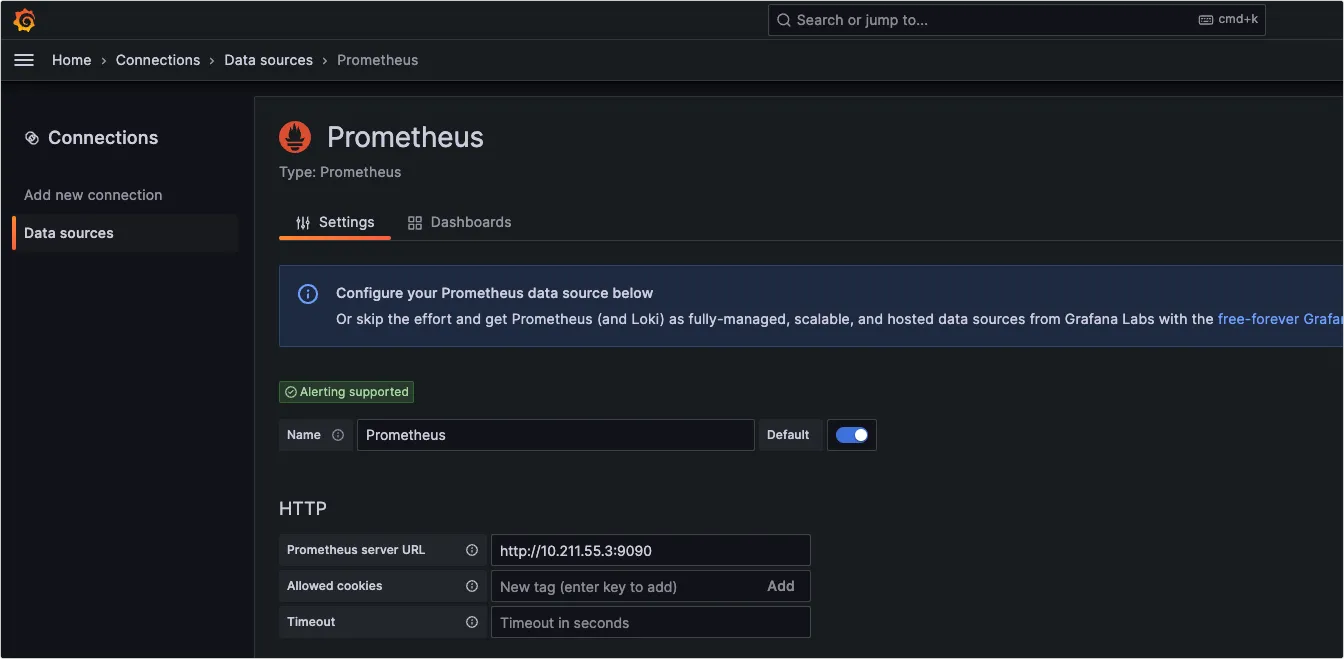
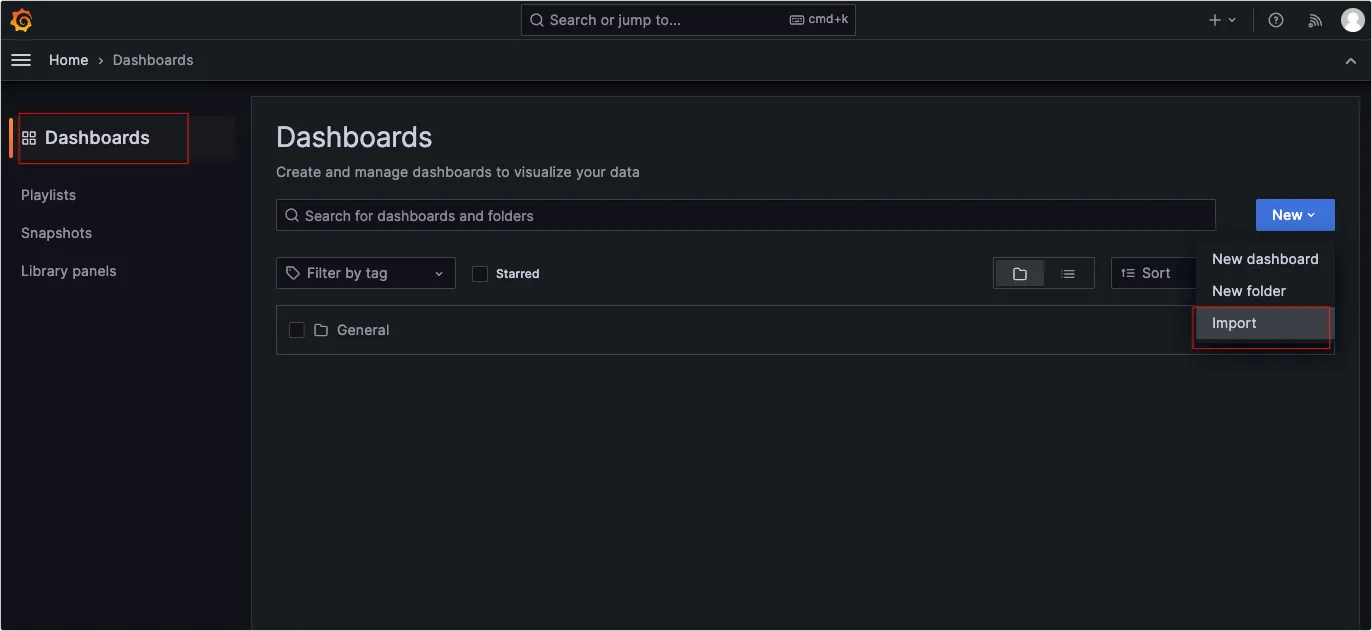
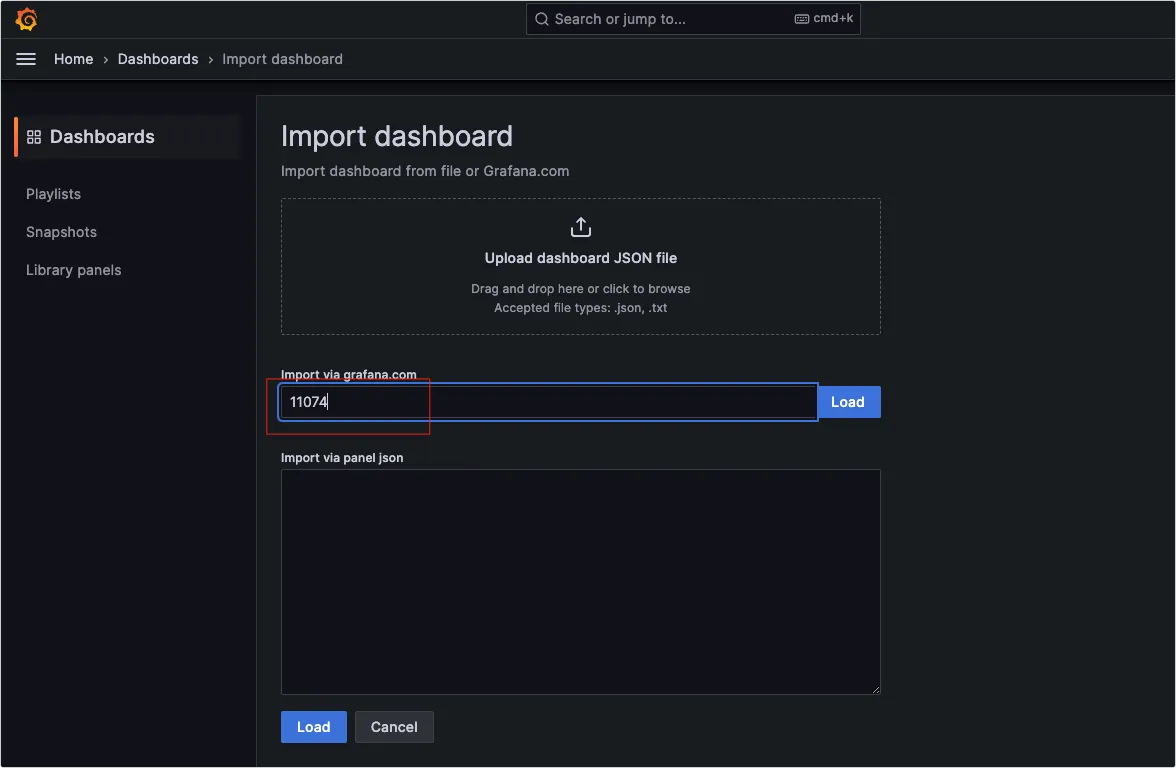
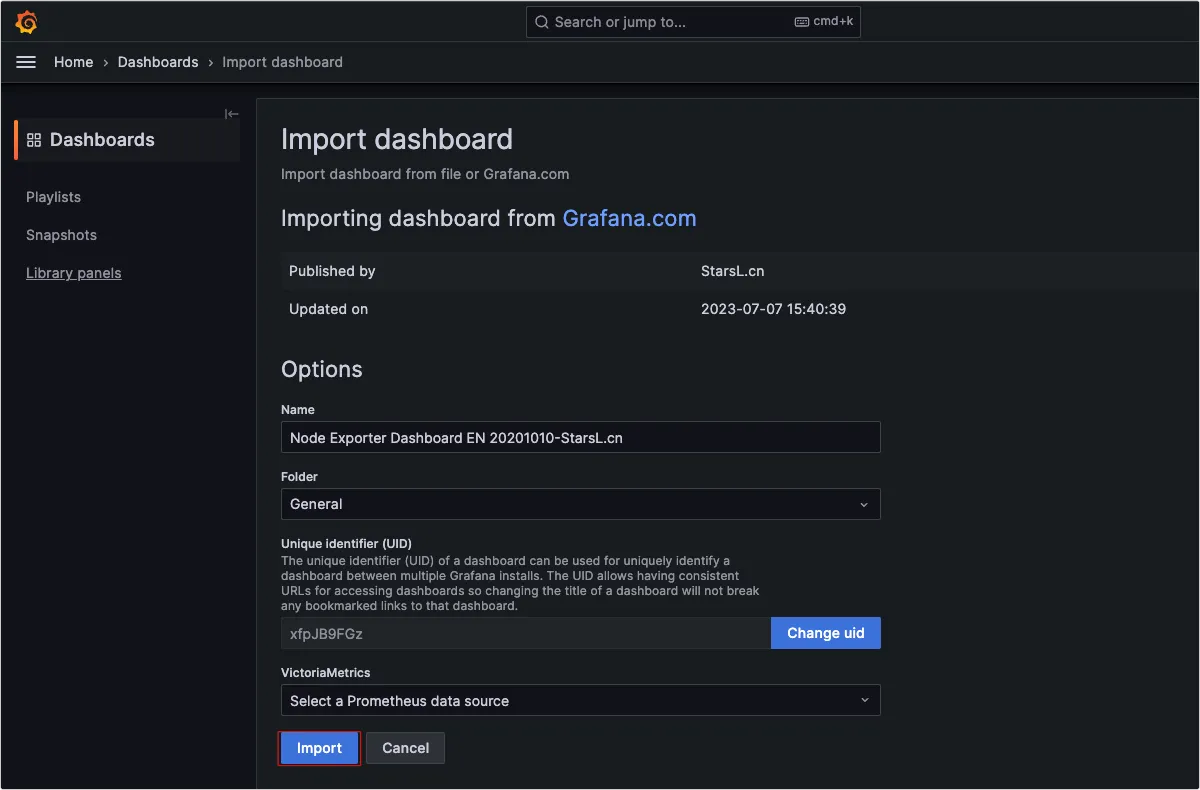
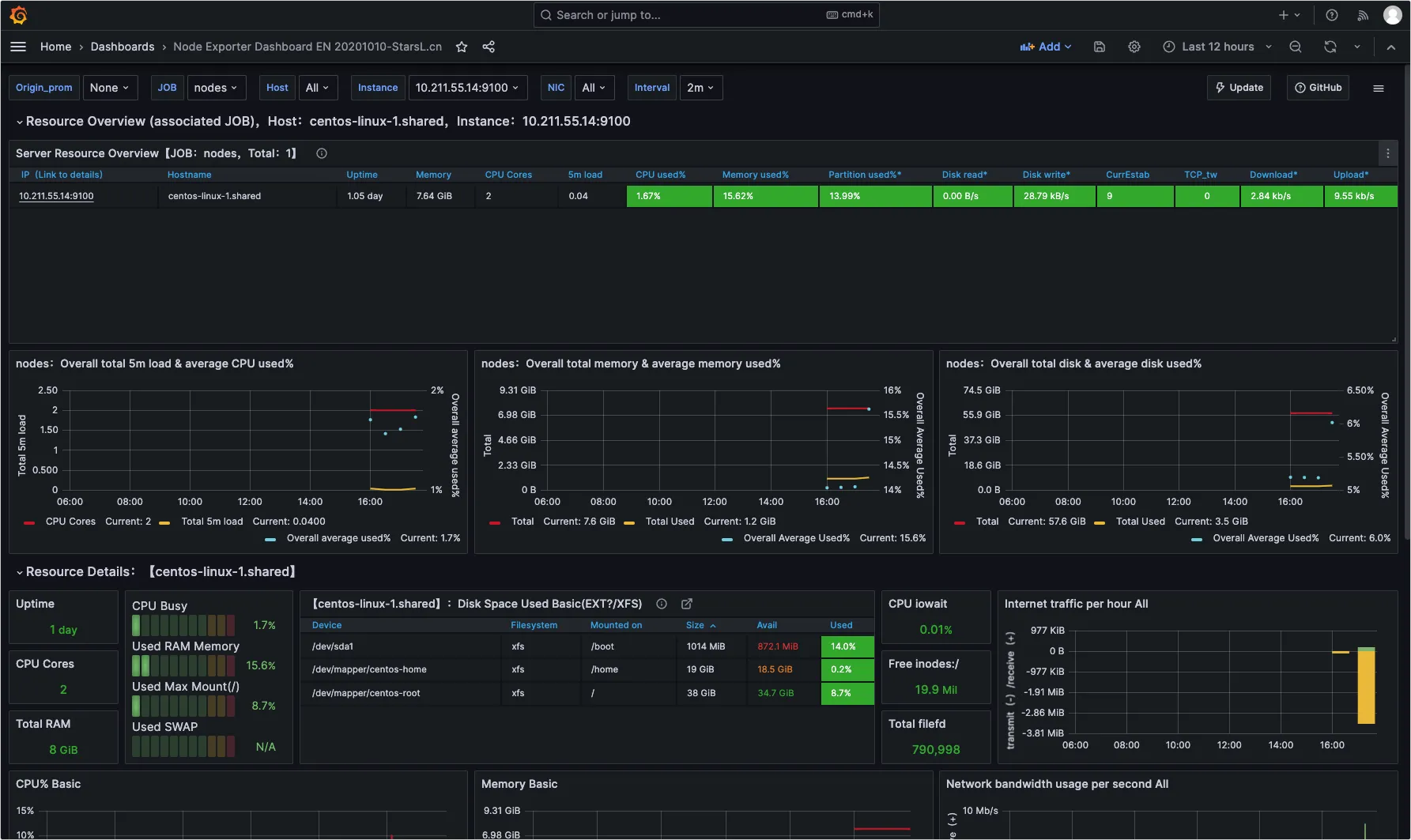
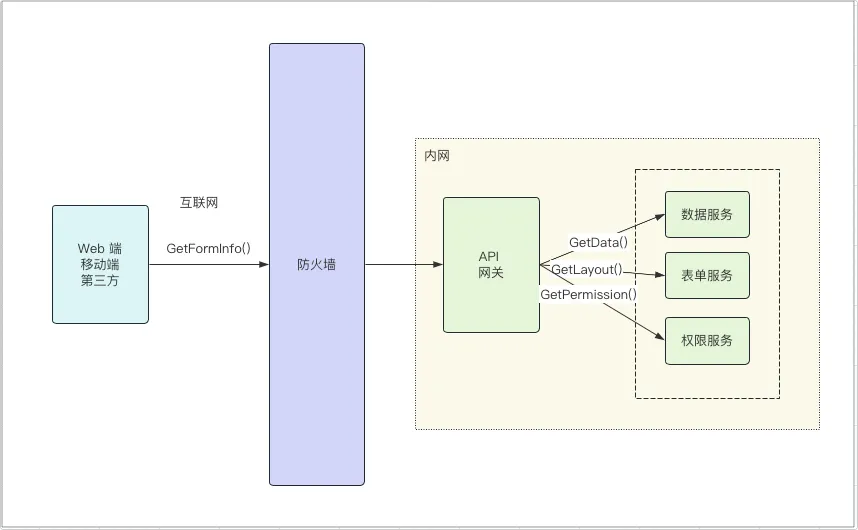
我们如果需要部署一个私有镜像仓库来使用,最简单的就是 registry ,一行命令就可以运行在 Docker 中,但功能也比较弱,如果想要私有镜像仓库功能更丰富些,可以使用 Harbor 。
本文简单介绍下 Harbor 的安装和使用。
环境
- 服务器:CentOS 7 ,Harbor 部署在内网,通过 nginx 反向代理发布到外网使用
- Harbor:2.9.1
- docker:23.0.5
安装
1、如果没有安装 wget ,先执行下面命令安装:
1 | yum install -y wget |
2、下载包:
1 | wget https://github.com/goharbor/harbor/releases/download/v2.9.1/harbor-offline-installer-v2.9.1.tgz |
如果无法通过 wget 进行下载,可以直接到 Github 网站:https://github.com/goharbor/harbor/releases/ 进行下载,然后拷贝到服务器中:
3、执行下面命令进行解压:
1 | tar -xvf harbor-offline-installer-v2.9.1.tgz |

4、执行下面命令新建目录,并将程序文件复制到目录中:
1 | mkdir /opt/harbor |
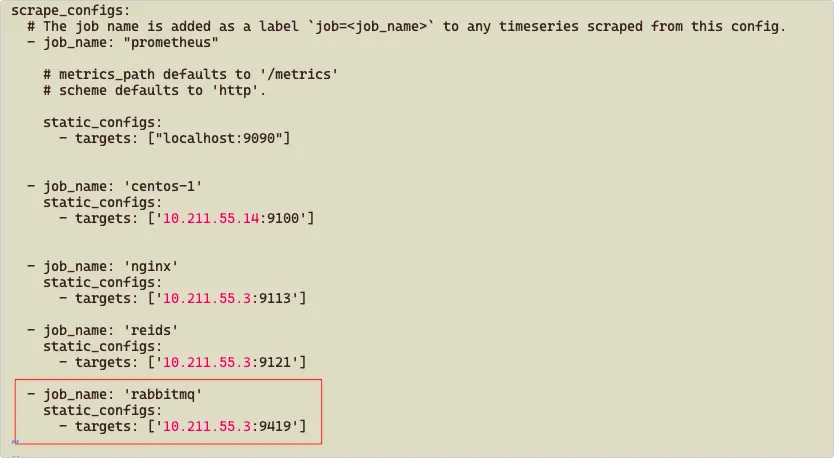
5、修改 Harbor 配置文件:
1 | cp -ar harbor.yml.tmpl harbor.yml |
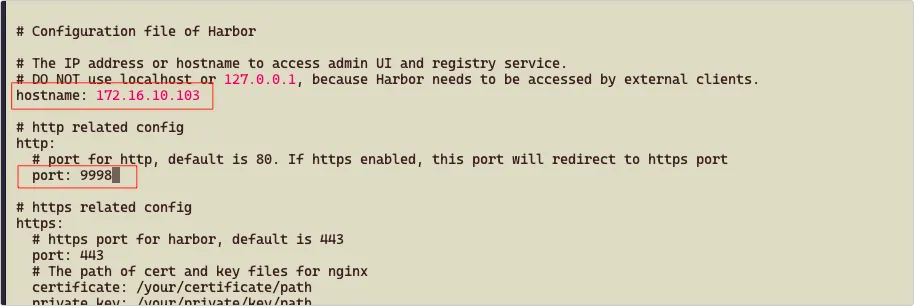
- hostname:如果只是内网访问,设置为内网 IP,如果需要外网访问,就必须设置为外网域名或 IP
- port:Web 访问的端口
6、编辑完配置文件,接下来在 harbor 目录下安装 Harbor。先进行预处理:
1 | ./prepare |
7、执行下面命令进行安装:
1 | ./install.sh |
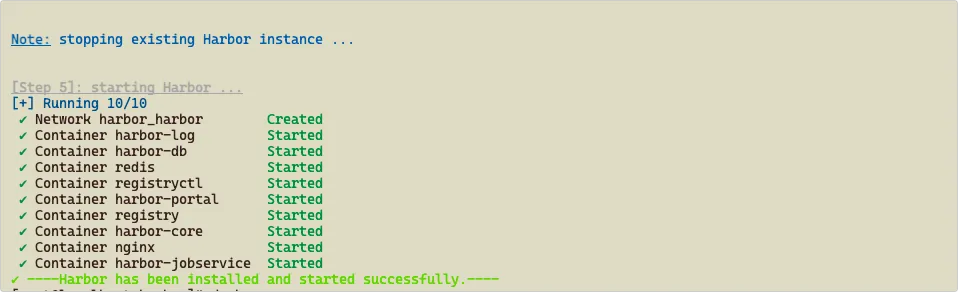
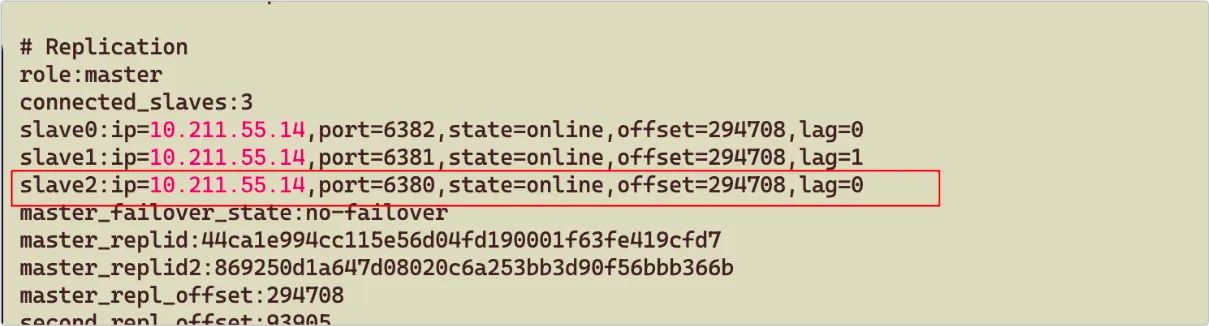
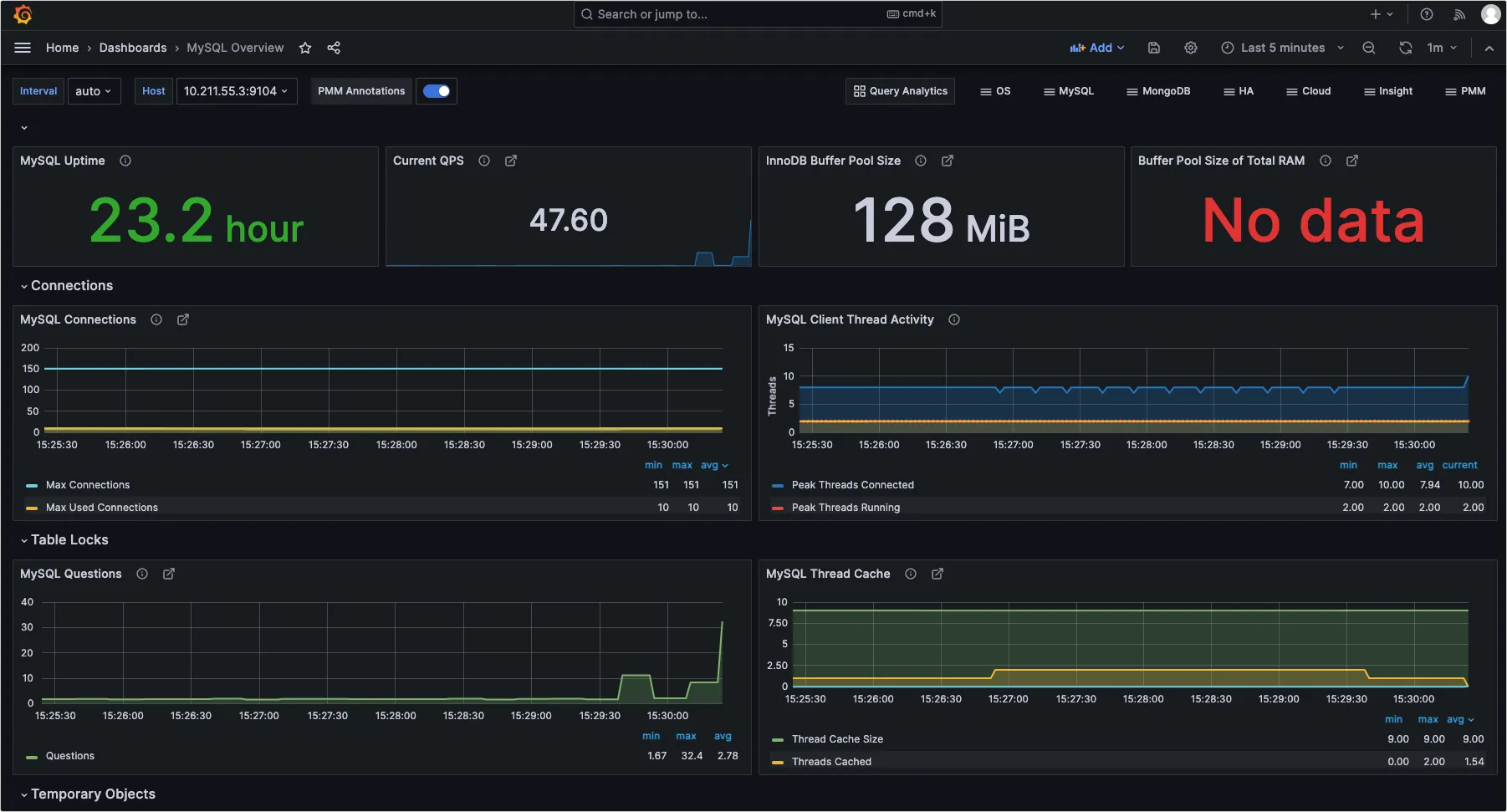
8、稍等一会,执行 docker-compose ps ,如果所有容器的状态都是 healthy ,说明正常:

9、登录后界面如下:
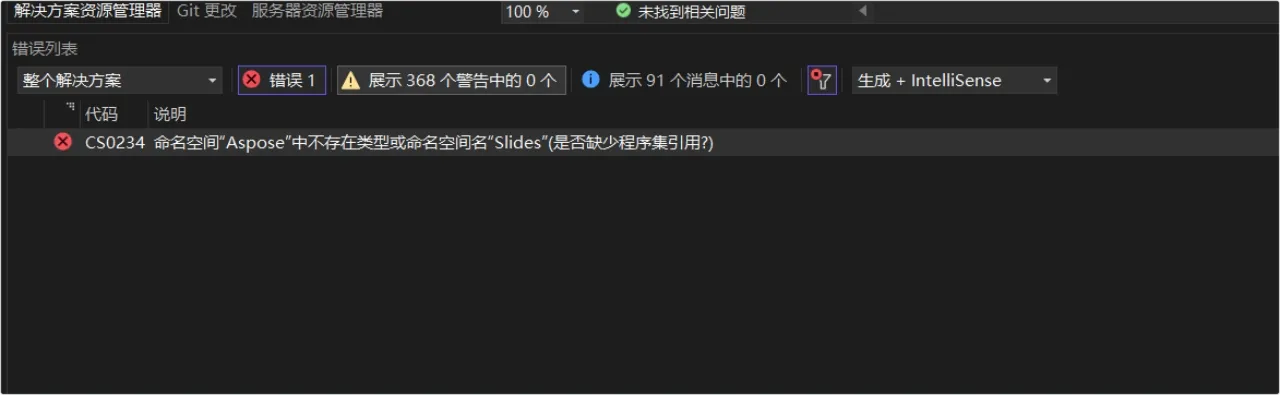
问题
1、内网不能登录
安装完成后,在外网使用 docker login 发现不能正常登录,于是先进内网进行验证,发现内网也不能登陆,提示信息如下:
[root@localhost data]# docker login 172.16.10.103:9998
Username: admin
Password:
Error response from daemon: Get “https://172.16.10.103:9998/v2/": http: server gave HTTP response to HTTPS client
需要将内网服务器 IP 和端口配置到 daemon.json 文件中,执行下面命令进行配置:
1 | sudo tee /etc/docker/daemon.json <<-'EOF' |
然后执行下面命令重启生效:
1 | sudo systemctl daemon-reload |
再次登录:
[root@localhost docker]# docker login 172.16.10.103:9998
Username: admin
Password:
WARNING! Your password will be stored unencrypted in /root/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credentials-storeLogin Succeeded
这个不仅仅是内网,哪台机器需要进行登录操作,都需要进行上面的配置。
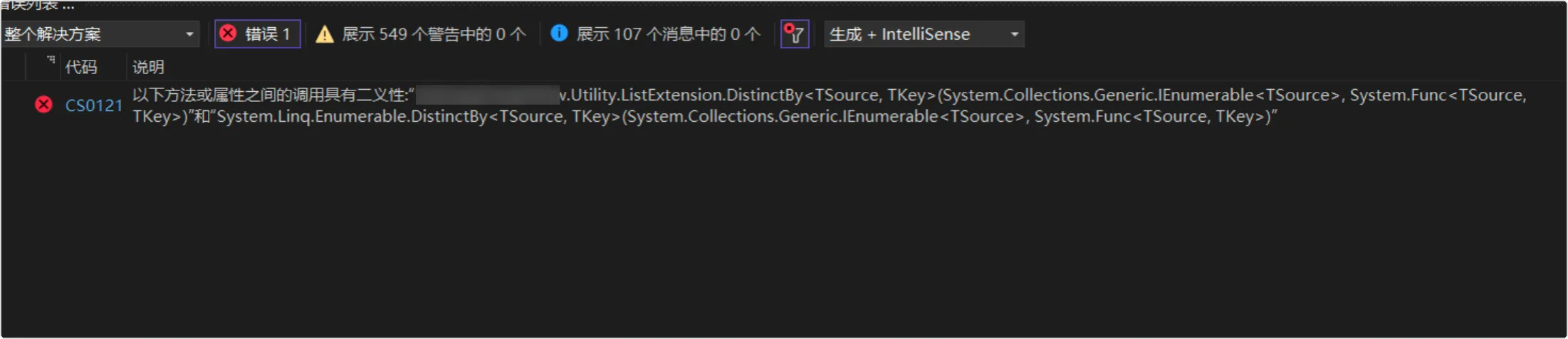
2、外网不能登录
当内网正常后,发现外网依然不能正常登录,提示如下:
fengwei@fengweideMBP ~ % docker login hub.fwhyy.com:1234
Username: admin
Password:
Error response from daemon: Get “http://hub.fwhyy.com:1234/v2/": Get “http://172.16.10.103:9998/service/token?account=admin&client_id=docker&offline_token=true&service=harbor-registry": context deadline exceeded (Client.Timeout exceeded while awaiting headers) (Client.Timeout exceeded while awaiting headers)
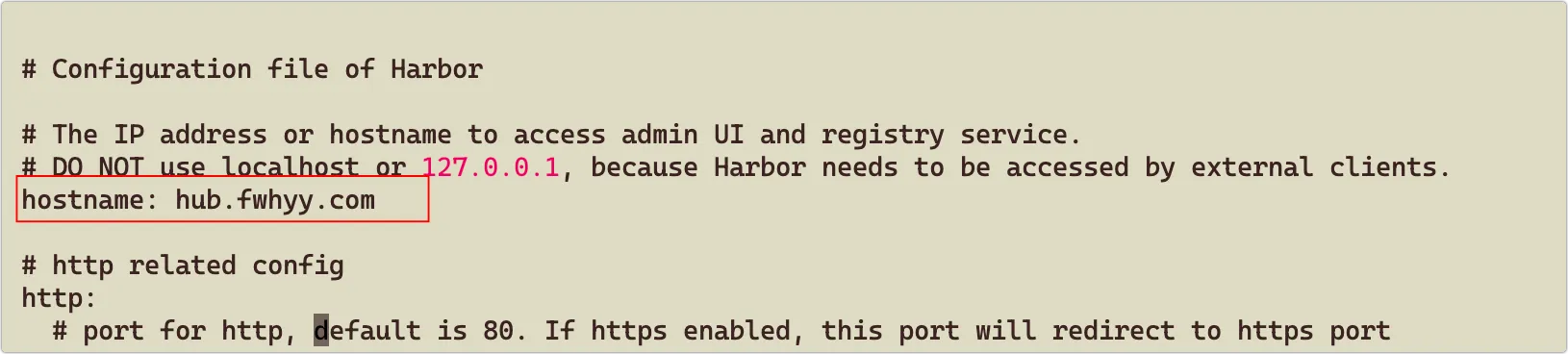
解决这个问题需要修改 harbor.yml 配置,将 hostname 修改为外网的 IP 或域名(不需要加端口):
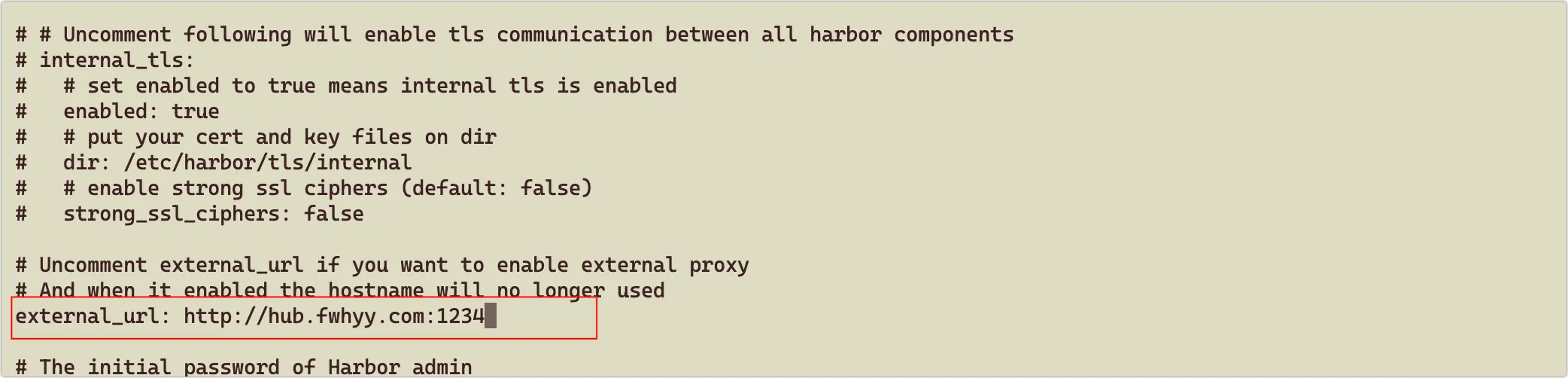
将 external_url 修改为外网访问的地址(需要加上端口):
修改完后需要重启 Harbor,执行下面命令进行重启:
1 | cd /opt/harbor |
外网服务器的 nginx 配置如下:
1 | server { |
使用
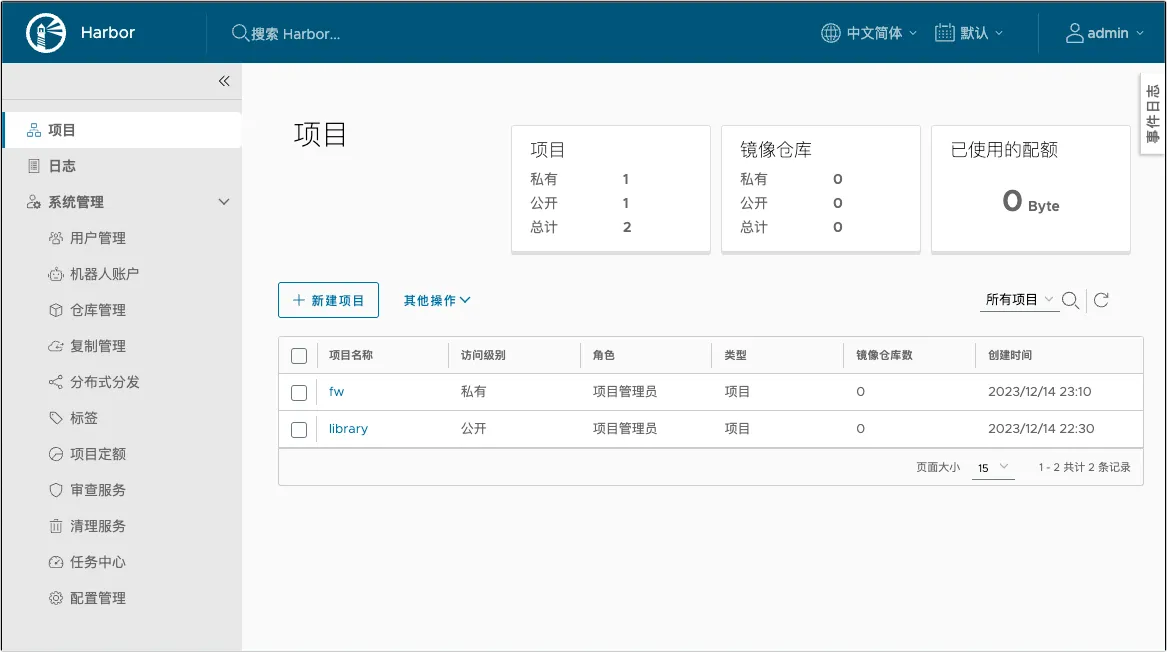
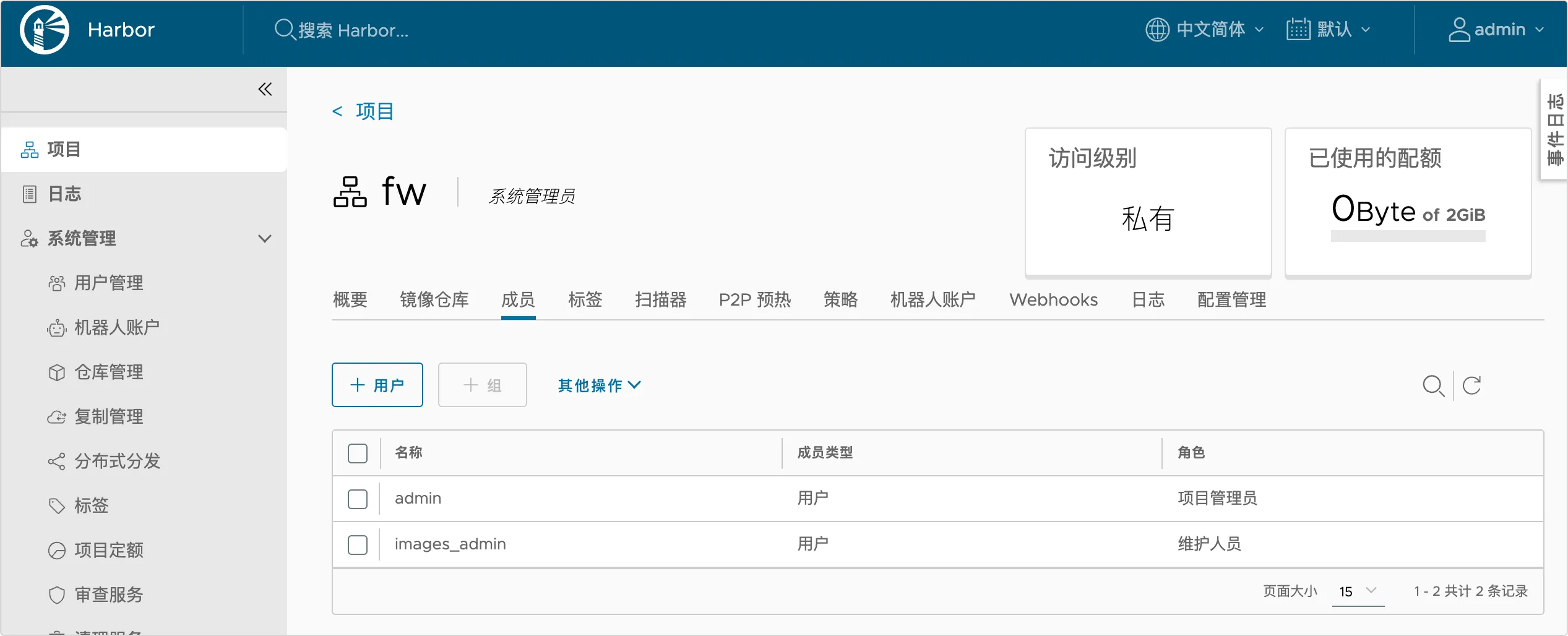
Harbor 里功能比较多,常用的有项目、用户管理、项目定额。
- 项目:可以针对不同的项目单独创建,每个项目都有自己的镜像地址
- 用户管理:可以维护用户,不同的项目可以设置不同的维护人员
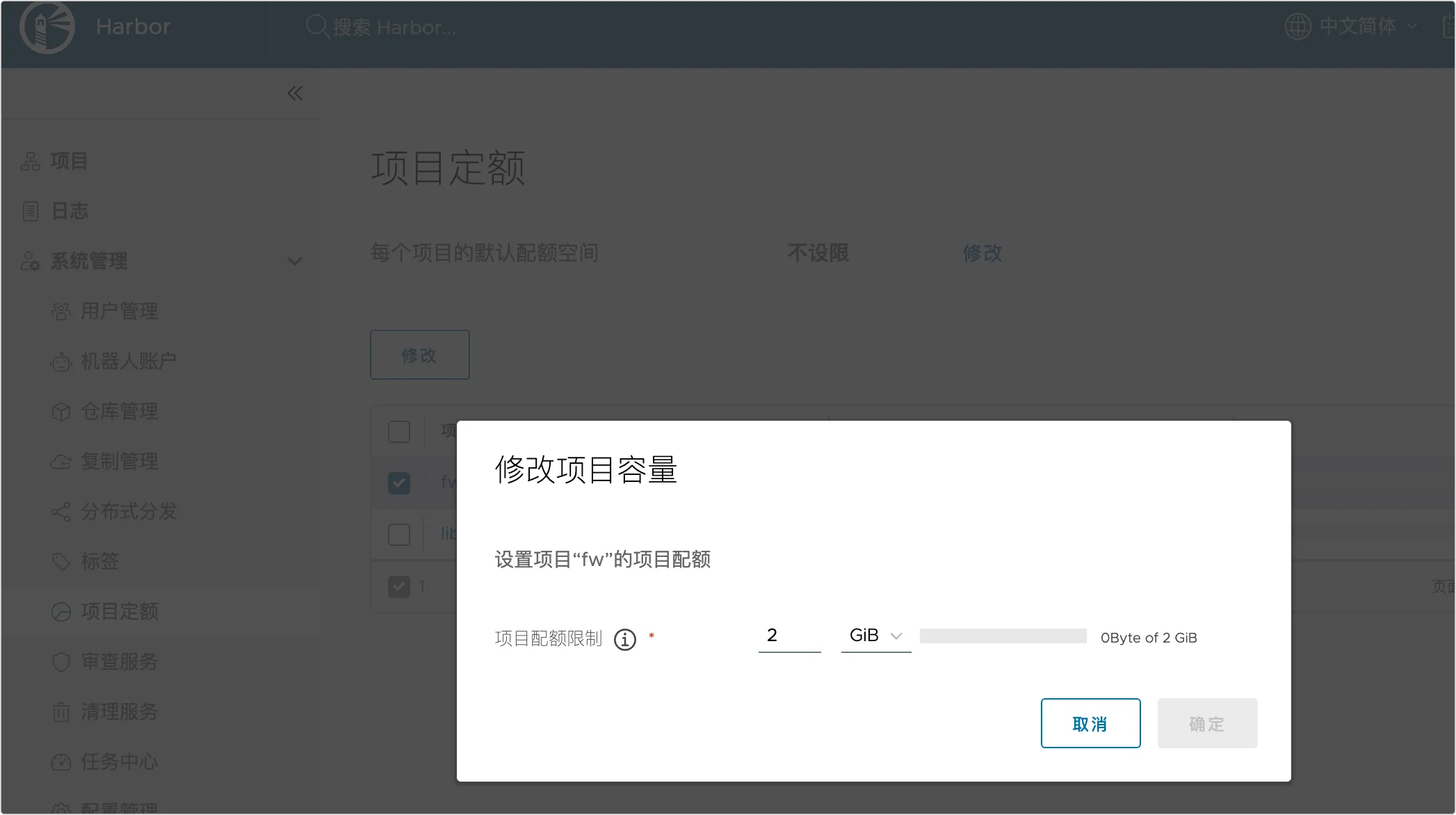
- 项目定额:设置项目对应的镜像仓库最大空间容量
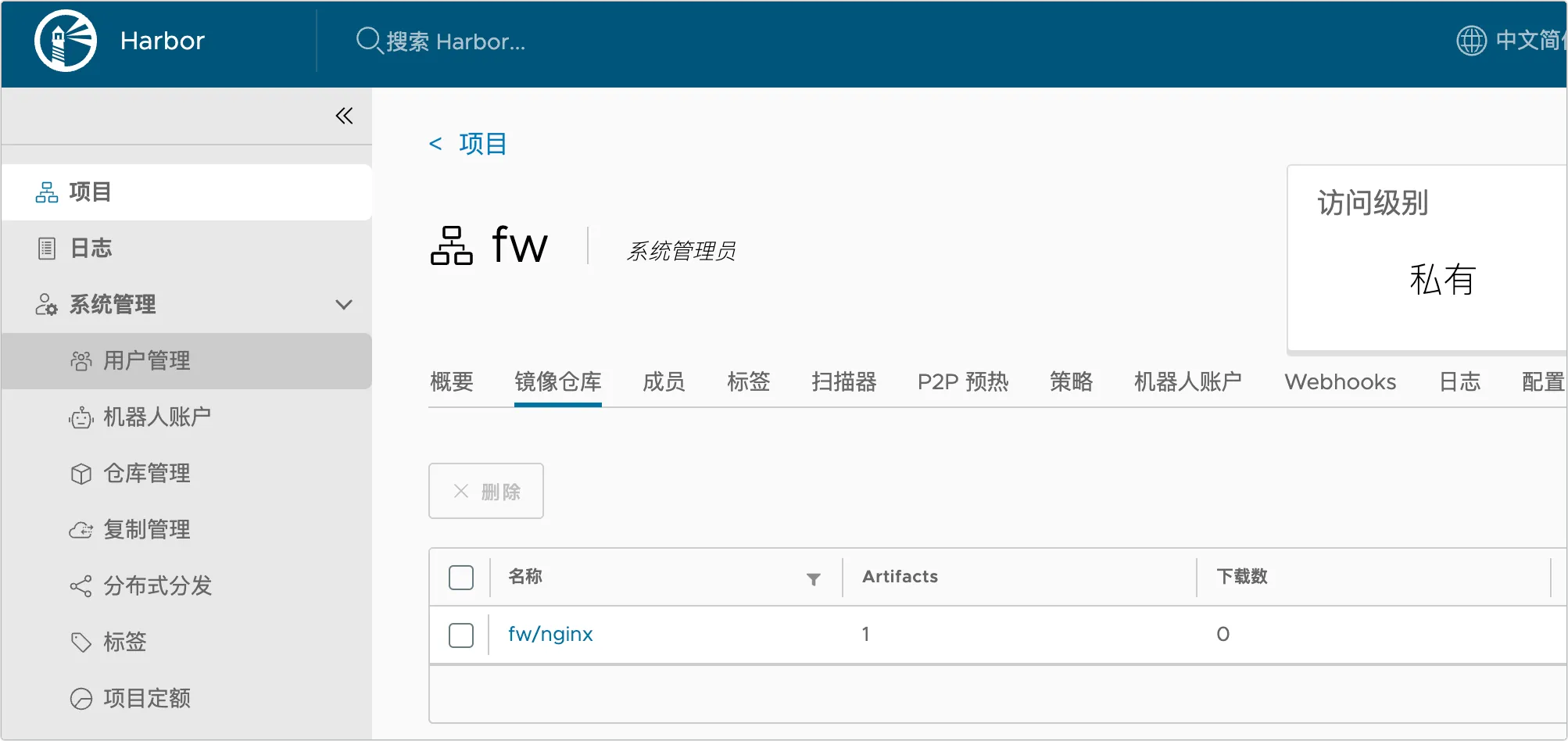
下面就按照步骤将一个镜像推送到 Harbor 中。
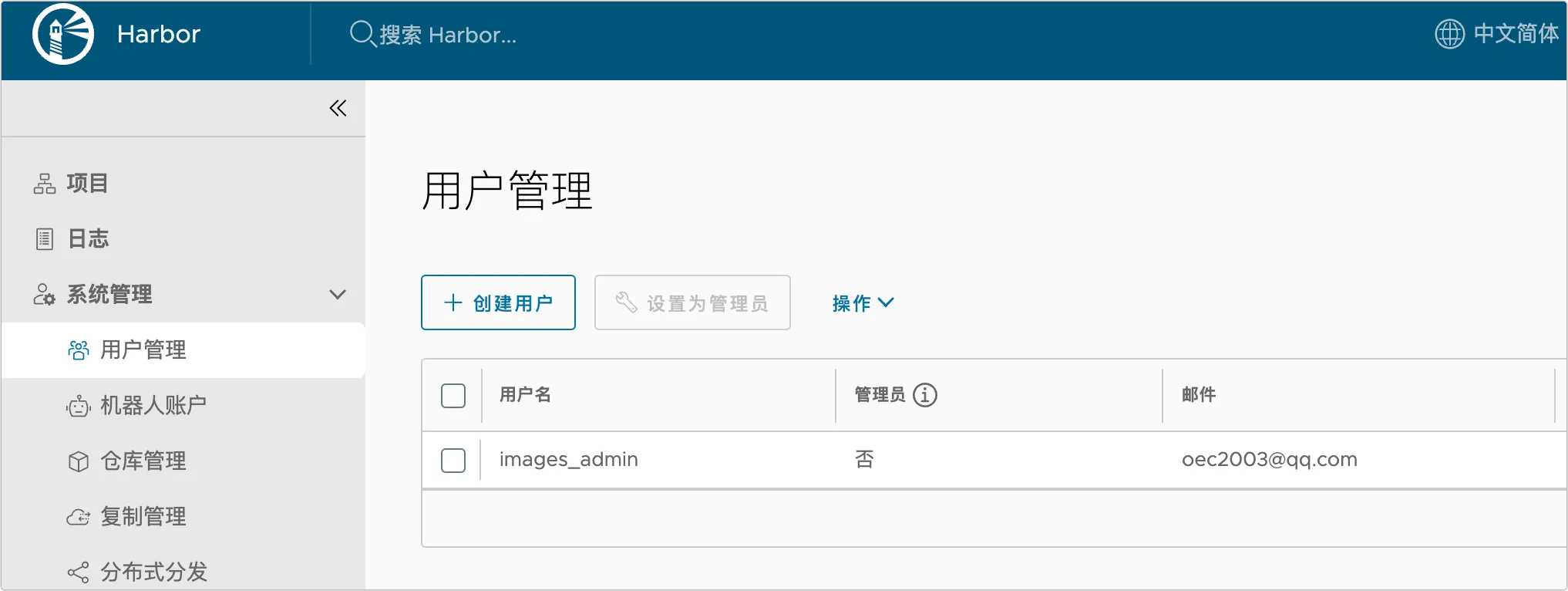
1、在用户管理中创建名称为 images_admin 的用户:
2、在项目中创建名称为 fw 的项目,并添加 images_admin 为项目的维护人员:
3、在项目定额中设置项目的配额大小为 2GB:
4、先以一个 nginx 镜像为例,直接推送试试,命令如下:
1 | docker tag nginx:latest hub.fwhyy.com:1234/fw/nginx:latest |
因为没有登录,会提示没有权限推送:
The push refers to repository [hub.fwhyy.com:1234/fw/nginx]
b074db3b55e1: Preparing
e50c68532c4a: Preparing
f6ba584ca3ec: Preparing
01aaa195cdad: Preparing
2a13e6a7cca6: Preparing
370869eba6e9: Waiting
7292cf786aa8: Waiting
unauthorized: unauthorized to access repository: fw/nginx, action: push: unauthorized to access repository: fw/nginx, action: push
5、使用下面命令进行登录后再进行推送:
1 | docker login hub.fwhyy.com:1234 |
登录后,就可以正常推送了,登录进入系统,可以看到在项目的镜像仓库中已经可以看到了: